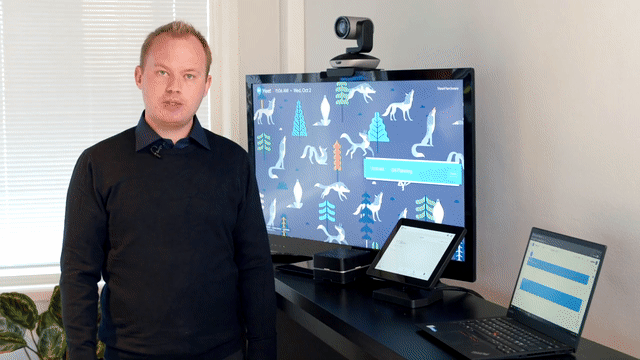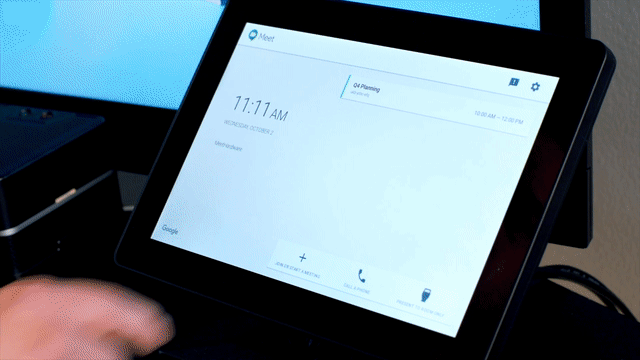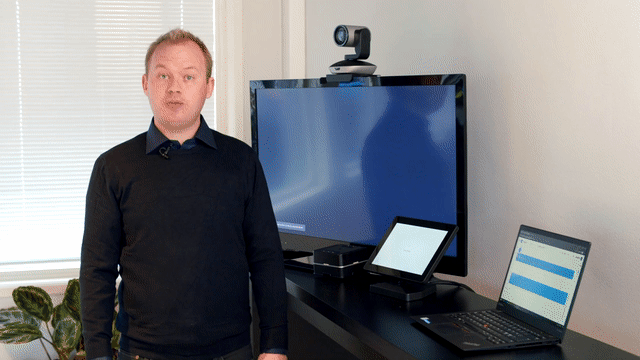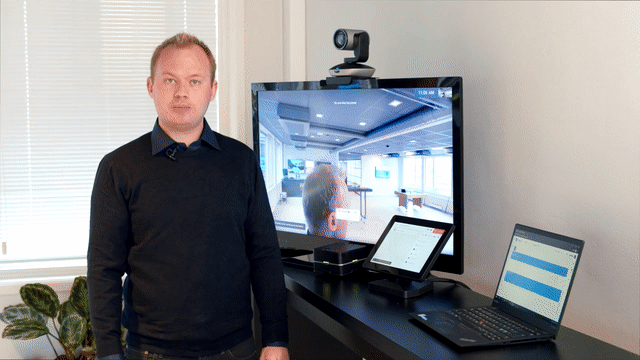
.png?width=700&name=Pexip-Connect-for-Google-Single-Screen-blog%20(1).png)
Content types
- Customer story
- Product sheet
- Product update
- White paper
- Guide
- eBook
- Report
- Webinar
- Podcast
- Article
- News
- Clear
Industries
- Defense
- Government
- Judicial
- Healthcare
- Financial services
- Enterprise
- Retail
- Clear
Products
- Connect
- Secure Collaboration
- Secure Meetings
- Video Platform
- Room Management
- Secure Meetings for Justice
- Business Continuity
- Engage
- Clear
Use cases
- Meet & collaborate securely
- Google Rooms interop
- Zoom Rooms interop
- Teams Rooms interop
- Standardize on Teams
- Private AI
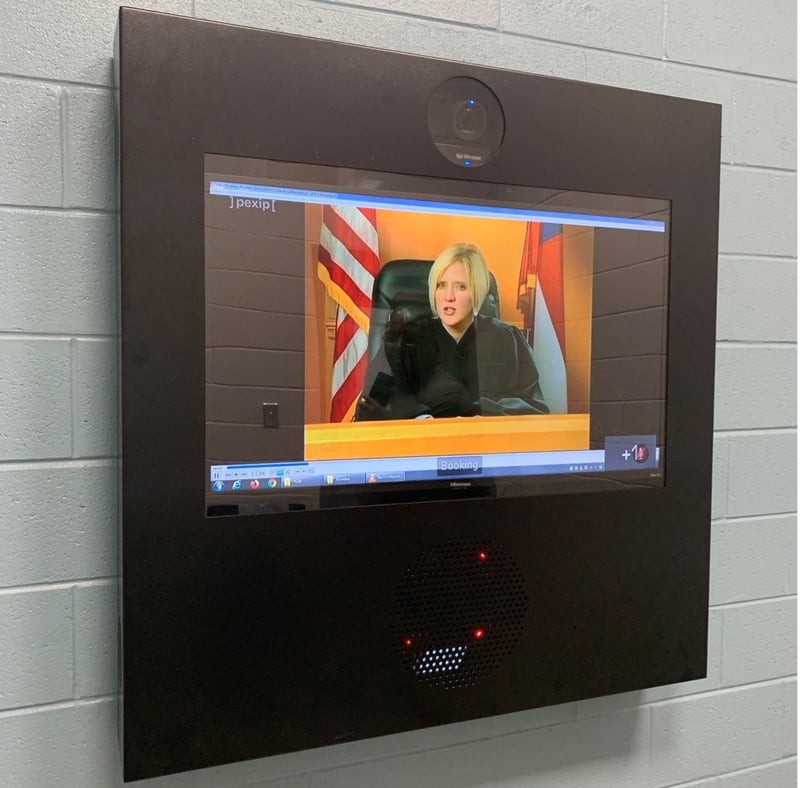
- Digital courtrooms
- Personalize customer engagement
- Clear
-
 Article
ArticleThe complete guide to secure video conferencing

-
Article
What makes a meeting secure?
-
Article
A better way for UK police to join CVP court hearings
.png?width=41&name=Untitled%20design%20(25).png)
-
Article
Ensuring legal video meetings work across clients, courts, and counsel

-
Article
Open source and sovereign collaboration: who carries the responsibility?

-
Article
Google’s built-in interop and Pexip: What’s the difference?

-
Article
Untangling the video interop market – here’s what IT leaders need to know
-
Article
Virtual courts and remote hearings: How is video conferencing shaping the future of law?
-
Article
How does a virtual court work and what is a video arraignment?
-
Product update
Pexip Infinity v39: All about smarter controls, more choice, and stronger security
-
Article
What Norway’s new Digital Security Act means for leaders

-
News
Smarter, more inclusive meetings with Private AI for secure environments
-
Guide
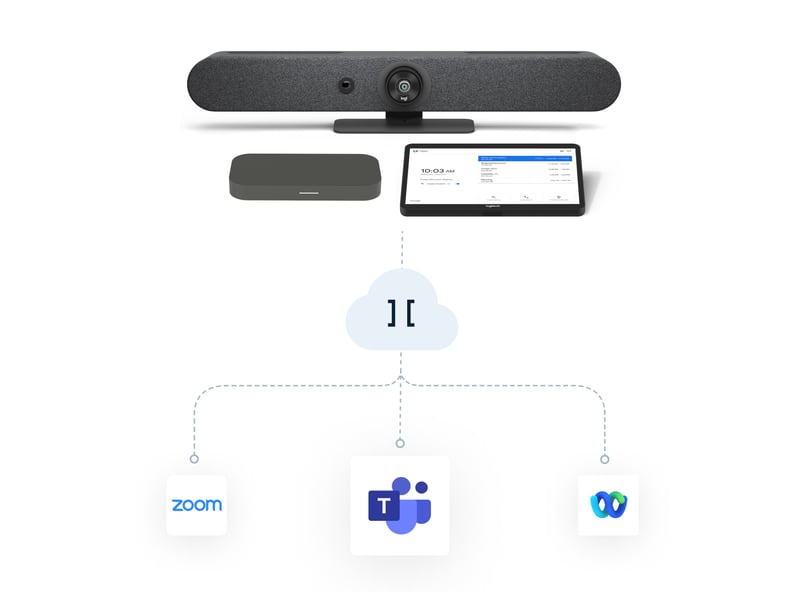
How to join Microsoft Teams meetings from your Google Meet hardware (GMH)

-
Product sheet
Pexip Connect for Google Meet and Meet hardware
Oct 3, 2025 -
News
Pexip Connect for Google Meet hardware now available
-
News
Pexip strengthens leadership team with tech executive Audhild Andersen Randa
-
News
Pexip brings secure video meetings to Mattermost’s collaboration platform
-
Article
The real cost of technical delays in virtual sales meetings

-
News
Pexip apps for iOS and Android now support secure collaboration in high-trust environments
-
Article
Why interoperability still matters more than ever in the age of Zoom and Teams
-
Article
Universal interoperability in enterprise video collaboration
-
Article
When secure becomes simple, security works
-
Article
Pexip makes secure meetings accessible to everyone
-
Article
How Pexip and Virtru are redefining secure real-time communication in defense environments
-
Article
Germany’s blueprint for Europe’s digital future. Sovereign. Resilient. Interoperable.

-
Product sheet
Pexip Secure Meetings for Defense
Jul 25, 2025 -
Product sheet
Pexip Secure Meetings for Government
Jul 25, 2025 -
Product sheet
Pexip Secure Meetings for Healthcare
Jul 25, 2025 -
Product sheet
Pexip Secure Meetings for Justice
Jul 25, 2025 -
Product sheet
Pexip Connect Essentials
Jul 25, 2025 -
Product sheet
Pexip Connect Standard
Jul 25, 2025 -
Product sheet
Pexip Connect for Government
Jul 25, 2025 -
Product sheet
Pexip Secure Meetings for Enterprise
Jul 25, 2025 -
Product sheet
Pexip for Business Continuity
Jul 25, 2025 -
Product sheet
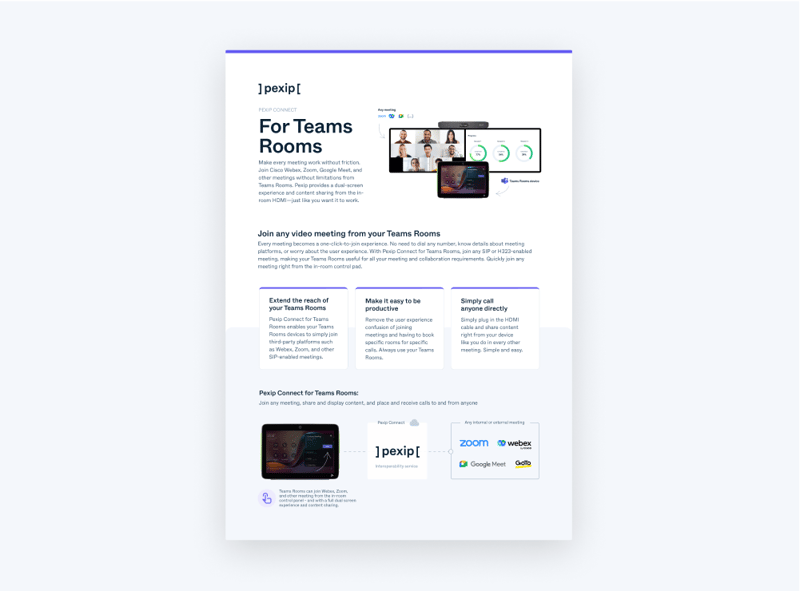
Pexip Connect for Teams Rooms
Jul 25, 2025 -
Product sheet
Pexip Connect for Zoom Rooms
Jul 25, 2025 -
Article
Pexip Infinity v38: Lower compute costs, more control, and a modern meeting experience
-
News
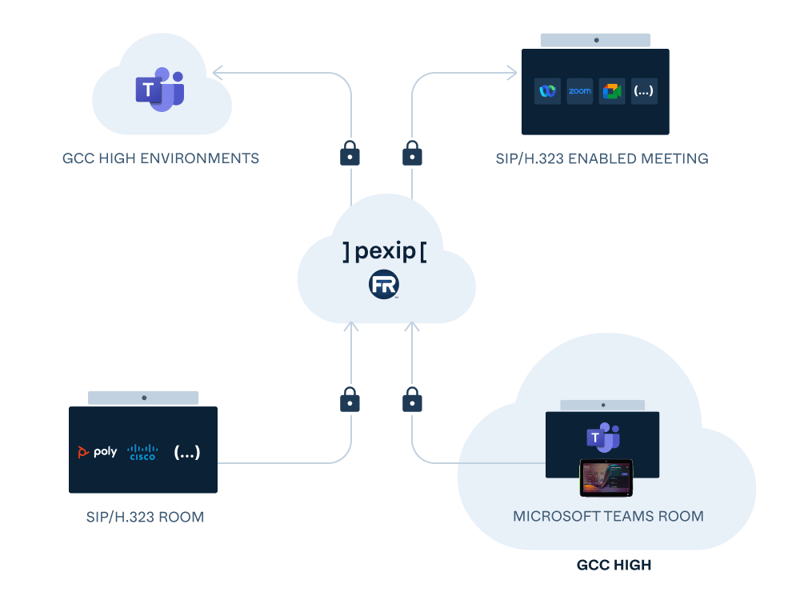
Join meetings in GCC High with FedRAMP Authorized interop

-
Product update
Pexip is rolling out a new generation of video conferencing apps for sovereign and air-gapped environments
-
Customer story
Transforming healthcare: The game-changing benefits of RAVI and Pexip integration
-
Article
AI is turning your video calls into a data risk – here’s what you need to know
-
Article
Why data-centric security is the future of defense collaboration

-
Article
Integrating Teams meetings into Zoom Rooms for a national retail organization
-
Article
Does ‘Made in Europe’ matter for secure collaboration? We think so.

-
News
Pexip brings secure collaboration to Bleu’s trusted cloud
-
Article
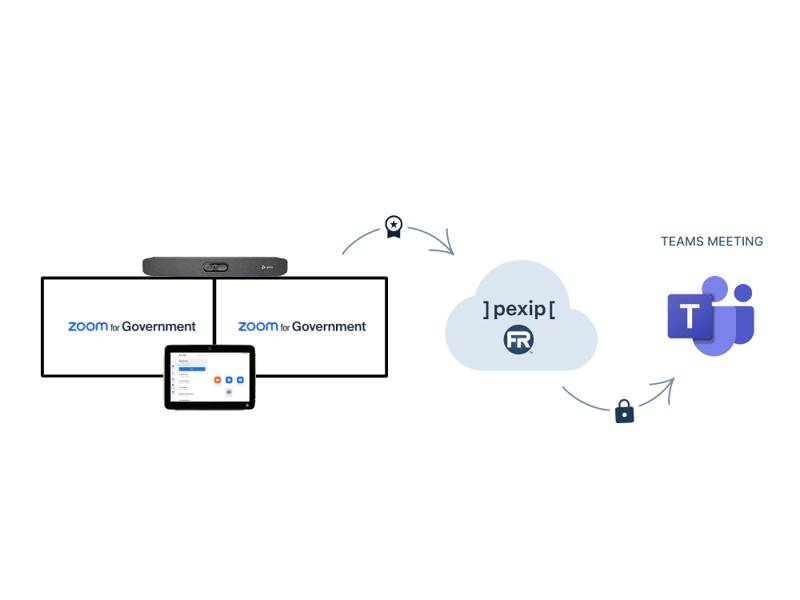
Use Zoom for Government Rooms to join Teams meetings – all in a FedRAMP Authorized environment
-
Article
Mission video is redefining real-time collaboration for defense at the tactical edge

-
Customer story
Giving seniors the 24/7 care they deserve through ‘teleassistance’
-
Article
The meeting platform could become a liability

-
Guide
Pexip Service Security and Privacy Whitepaper

-
Article
When ‘secure enough’ doesn’t cut it
-
Customer story
How the French Development Agency (AFD) solved critical sovereignty, interoperability, and bandwidth issues in video conferencing
-
Guide
Buyer’s guide to secure video collaboration
-
Customer story
Bridging the Zoom - Teams divide: How a financial institution modernized collaboration with Pexip

-
Article
Use your Google Meet hardware to join Teams, Zoom and Webex meetings
-
Article
Why Europe’s embracing digital sovereignty in the face of rising threats
-
Guide
Access control in regulated industries
-
Article
Who has access to your video meeting?
-
Article
PowerPoint Live and direct chat support enhance collaboration in Pexip Infinity v37
-
White paper
How to optimize your zero trust environments for secure video conferencing
-
Article
Are your open systems a threat to video conferencing security?
-
Article
See PowerPoint Live slides in CVI-enabled meeting rooms
-
Article
Secure, mission-ready video collaboration for defense
-
Article
Connecting Dutch hospitals with secure and high-quality video

-
Article
Solving video conferencing challenges in the higher education sector
-
Article
3 key trends defining video collaboration in defense
-
Article
What NIS2 means for your cybersecurity strategy
-
Article
Your video meeting is secure…but what about your AI data?
-
Article
Tired of Zoom Rooms and Teams compatibility issues at your school? Here’s the fix
-
Article
Help build resilience against deepfake video calls with smart access controls
-
Article
Why video is now a battlefield asset, not just a communication tool
-
Article
Defense cannot rely on just any video meeting system
-
Article
Is your video conferencing solution GDPR compliant?
-
Article
So, AI solves your problem…but now you have a new one
-
Guide
Modernize your video conferencing infrastructure for today’s meeting needs
-
Article
Build it vs. buy it – what’s the best way to integrate video calling in your workflows?
-
News
Pexip joins Zoom’s ISV Exchange program

-
Product update
Pexip v36 proves that modern functionality and privacy go hand-in-hand
-
Article
Control meetings through your Poly touch panel
-
Customer story
How Pexip connected video meeting solutions across the sprawling Aix-Marseille-Provence region
-
Article
Pexip launches Private AI for secure video meetings
-
Article
A step-by-step guide to enable Microsoft Teams Rooms devices to join third-party meetings
-
Article
How can I trust my video meetings in the age of deepfakes?
-
Article
Entering a new era of secure, sovereign video meetings
-
Product update
Pexip Connect for Teams Rooms is now available
-
Article
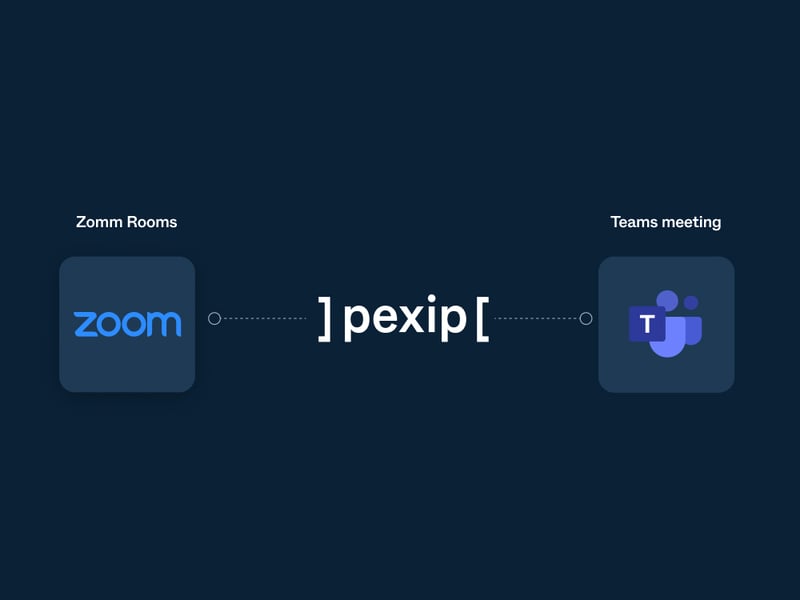
A step-by-step guide to join Teams Meetings from Zoom Rooms using Pexip Connect
-
Article
Pexip and LanguageLine: Bridging critical gaps in virtual healthcare
-
Article
Pexip launches Secure Scheduler for Web
-
Article
Easily build secure video apps with Pexip’s video calling SDKs
-
Article
Make secure video conferencing a quick win in your cybersecurity strategy
-
Article
Pexip now powers Teams interoperability for RingCentral Rooms
-
Article
How to Safeguard Personally Identifiable Information (PII) in video calling platforms
-
Article
Pexip leans into the future of cryptography with early FIPS 140-3 certification
-
Article
Why geo-fencing matters for secure video calling applications
-
Guide
Improve your FITARA cloud scores with Pexip

-
Article
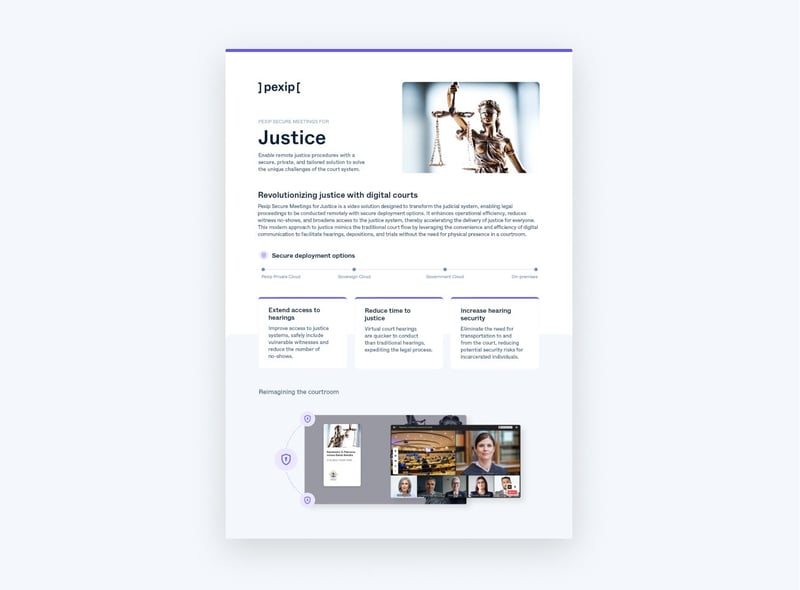
Pexip Secure Meetings for Justice launches new features to boost effectiveness of virtual courts
-
Product update
Pexip v35 raises the bar for user control and experience
-
Article
How to ensure resilient and secure video conferencing in the public sector
-
Guide
Migrating from Clariti: A guide to Secure Meetings for IT leaders
-
Article
Are your ‘cloud grades’ dragging down your FITARA scorecard?
-
Article
How to meet increasing sovereignty requirements for video communication in Europe
-
White paper
Complete guide to data sovereignty regulations
-
Article
Why self-hosted AI in video conferencing is essential to remain compliant in regulated industries
-
News
Pexip recognized as a finalist for the 2024 Microsoft Commercial Marketplace Partner of the Year Award
-
Article
Make any video meeting a secure meeting in one simple step
-
Article
Pexip’s latest software update is all about enhancing the user experience

-
Article
The role of trust in cybersecurity principles is to have none
-
Article
Pexip and Microsoft improve interop experience for Teams Rooms

-
Article
Pexip to deliver unmatched experience when joining Microsoft Teams meetings from a Zoom Rooms
-
Article
Cisco and Pexip partner to bring certified interoperability to government agencies
-
Article
Did the customers win when Poly and Pexip decided to partner?
-
Article
How security conscious organizations can fill their Skype for Business gap

-
Article
3 steps to AI compliance
-
Article
Avaya selects Pexip to deliver secure video meetings
-
Article
How granular can you go when restricting and directing access in video conferencing?
-
Article
How to protect your video meetings from unauthorized access
-
Article
How the hybrid courtroom is changing justice systems around the world
-
Product update
Pexip Secure Meetings for Justice is ushering legal proceedings into the digital age
-
Product update
Pexip Infinity v34 puts more customization options in the hands of the users
-
Article
Why does server-side vs client-side data processing matter for AI?
-
Article
Lost in translation: How NVIDIA AI supports natural language processing and real-time translation in video meetings
-
Article
Who should care about AI privacy and security?
-
Article
Why is private and secure AI so important for video conferencing?
-
Article
Collaboration and innovation are key to building stronger defenses against deepfake attacks

-
Article
The most meaningful changes for women happen in everyday work life

-
Article
The power of secure video solutions for financial services
-
Article
Everything you need to know about video interoperability
-
Article
Teams-like experiences – a massive upgrade coming your way
-
Article
Secure video meetings for law firms: how to ensure your confidential meetings stay that way
-
News
Pexip works with Lenovo to extend Teams Rooms capabilities
-
Article
How security-conscious organizations approach video conferencing
-
Article
The power of being a Microsoft Teams certified video conferencing technology leader

-
Article
5 cyber-security predictions for 2024
-
Article
Choosing a collaboration tool to gain data sovereignty
-
News
Pexip releases programmable video platform beta to invited users
-
Article
What’s your back-up plan when your video conferencing system goes down?
-
Article
Which hosting option is best for your secure video conferencing?
-
Article
5 reasons that organizations are turning to self-hosted video solutions
-
Article
Does the EU’s new cyber security directive NIS2 impact you?
-
Article
All you need to know about secure, self-hosted video conferencing
-
Product update
Infinity 33 introduces breakout rooms and AI features
-
Article
FaceTalk powered by Pexip is accelerating virtual doctor - patient care in the Netherlands
-
Article
Your video meeting data is for your eyes only
-
Customer story
How Pexip Engage helped realize the strategic vision of vdk bank
-
Guide
How to master customer engagement: complete guide for high-involvement retailers
-
Article
How The Showcase brought the feeling of luxury shopping to the digital customer experience
-
Report
Exceeding client expectations with Pexip Secure Spaces
Aug 29, 2023 -
Article
Seamless collaboration: integrating Pexip with Nextcloud
-
Article
Would the principle of zero trust security have saved the Titanic?
-
Article
Pexip and Collaboard: Seamless whiteboard collaboration over video
-
Article
Enabling AI for secure and custom video environments
-
News
Pexip Government Cloud Attains StateRAMP Authorization
-
Article
The stakes have never been higher for telehealth companies when it comes to protecting patient data

-
Article
A smooth transition to video support is essential in the world of self-service banking
-
Article
5 ways that video adds value to your customer service
-
Article
Video technology is changing the way big purchases are made
-
White paper
The key to seamless Microsoft Teams meetings
-
Product update
Pexip enables direct 1:1 calling from Teams Rooms to all other video conferencing devices
-
Article
The right technology can help consultants avoid video meeting malfunctions
-
News
Pexip first to offer certified Microsoft Teams interop for U.S. Department of Defense
-
Article
5 data privacy regulations you should know when deploying collaboration tools
-
Article
5 things companies must consider before deploying collaboration tools
-
Article
Is your video conferencing solution FedRAMP®-authorized? Here’s why it matters
-
Article
How Pexip multiplatform video stimulates efficiency in law firms
-
Guide
A leader’s guide to getting business value out of video
-
Article
5 trends that are driving the rise of sovereign collaboration solutions
-
Article
An organization’s guide to compliant collaboration solutions
-
Article
Democratization of Technology: Living Through a Phase Shift
-
Article
A video meeting without branding is like a store without a sign
May 3, 2023 4 min read -
Article
Poly and Pexip – what this strategic alliance means for your organization

-
News
Pexip partners with Poly to expand cloud based communication
-
Article
Get the control of a self-hosted solution with the ease of deployment of a cloud service
-
News
Pexip Government Cloud Achieves FedRAMP® Authorization
-
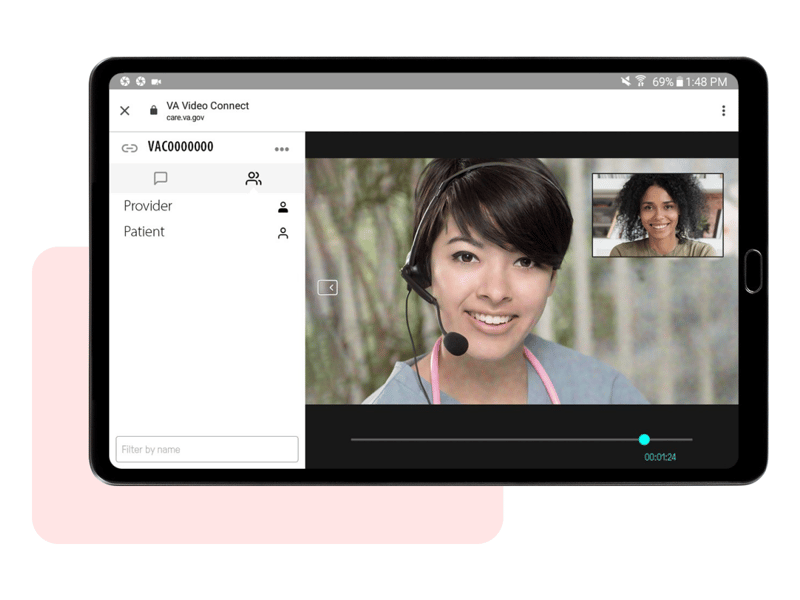
Customer story
Pexip enables veterans to connect with VA healthcare providers
-
News
Pexip now available on Genesys AppFoundry
-
Product update
Improved scheduling experience with the v2 plugin

-
Product update
Join any Teams meeting on any device with SIP Guest Join
-
Article
These are the privacy and security questions you should be asking in your company
-
Customer story
EGGS, now part of Sopra Steria, adopts Pexip’s Microsoft Teams integration
-
Article
Is your video platform secure enough for your most confidential conversations?
-
Customer story
Pexip helps Australia drive smoking cessation through video training

-
Product update
What's new in version 31 of Pexip Infinity?
-
Article
3 Pexip women share advice on life, careers and why gender balance matters
-
Article
4 benefits of automated appointment scheduling and virtual customer meetings
-
Product sheet
Pexip Engage for enterprise scheduling
Mar 4, 2023 2 min read -
Article
How to prevent major productivity losses when your IT systems go down
-
Customer story
How Vontobel enabled simplified and secure customer communication with Pexip
-
eBook
How retail banks can master customer engagement
Feb 21, 2023 -
Customer story
Fortune 50 Manufacturing Company
-
Customer story
Gas Transmission System Operator of Ukraine
-
Customer story
How VNZ optimized their customer experience with Pexip Engage
-
Article
Omnichannel customer engagement: How to exceed customer expectations
-
Article
Why is it essential to offer better customer advisor availability?
-
News
Pexip Virtual Courts Wins Frost & Sullivan Customer Value Leadership Award
-
Report
The leading virtual court solution
Feb 15, 2023 -
Article
How zero trust architecture can limit the impact of cyber attacks
-
Customer story
Norwegian Agency for Shared Services in Education and Research
-
Article
How to use customer booking insights to increase conversions
-
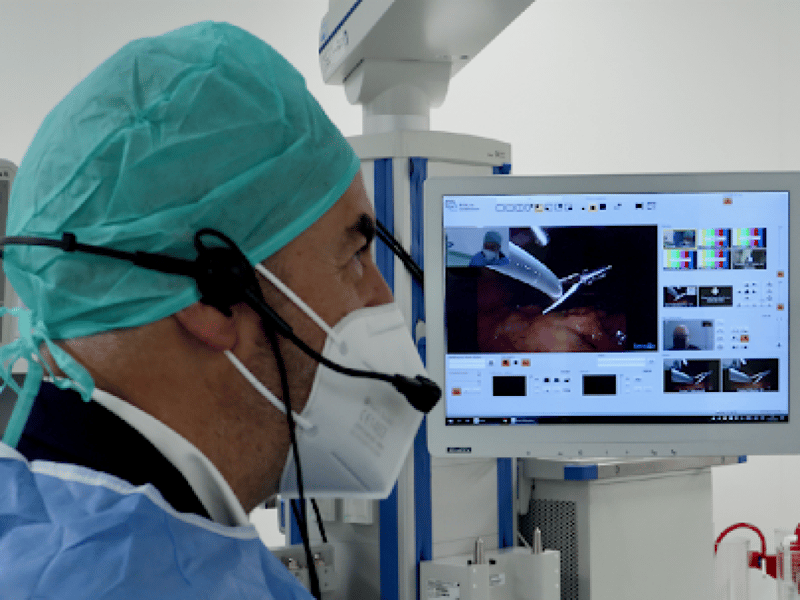
Customer story
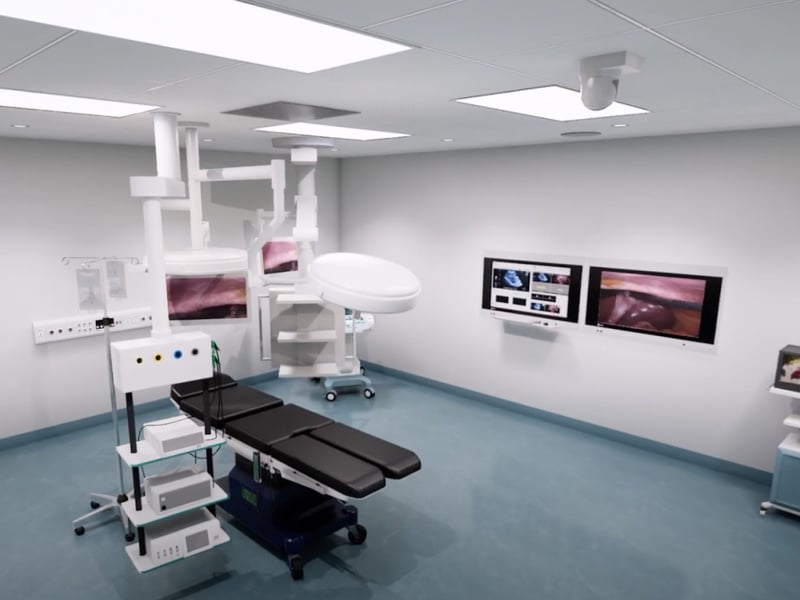
Pexip powers video surgical training in Spain
-
Article
Improve frontline worker safety and performance with extended reality (XR) wearables

-
Customer story
DFN enables its staff, research teams, and students to hold secure virtual meetings
-
News
Pexip strengthens commitment to information security and privacy with ISO 27001 and 27701 certifications
-
Article
What secrets do your call detail records reveal about your company?
-
Guide
A Business Leader’s Guide to Privacy and Security
-
Customer story
Gestational Diabetes Pathway provides easy and accessible virtual visits for pregnant women
-
Article
When failure of critical infrastructure isn’t an option, business continuity planning must take priority
-
Customer story
How ARRI adjusted for hybrid work demands with Pexip
-
Customer story
Pexip's security and reliability supports Ibermutua's interactive collaboration solution for surgeons
-
Article
Pexip experts’ 2023 predictions for the world of video tech
-
Article
How distributed architecture can improve the resilience of your organization.
-
Article
Supply chain cyber-attacks are on the rise. Is your organization prepared?
-
Customer story
APG utilizes existing hardware to improve the employee meeting experience for in-office, remote, and overseas workers
-
Customer story
How Solidaris created a more caring health insurance fund
-
Article
Reimagining the Future of Virtual Courts with Effective and Secure Video Collaboration

-
Article
How retail banks can win customers with scheduled video appointments
-
Article
Pexip protects you against cyber attacks
-
Customer story
Royal Belfast Hospital for Sick Children
-
Article
Leading in a changed world video series
-
Customer story
Pexip helped SynapSiS to enable equal access to education
-
Article
Healthcare patients continue to opt for video
-
Article
The 3 most common cybersecurity pitfalls we fail to remember
-
Customer story
Buying a dream home made easier with Pexip Engage
-
Product update
Unite your meeting rooms with a Teams like experience

-
News
Modern, on-premises meeting room management
-
Customer story
Northern Sydney Local Health District
-
White paper
How video is shaping the future of telemedicine
-
Article
How to deal with no show appointments?
-
Customer story
Parentia speeds up their digitization in a rapidly changing market
-
Customer story
Brilart exceeds their revenue targets with Pexip Engage
-
News
Pexip partners with Vbrick to bring secure video recordings to the enterprise
-
Article
Video meeting basics: How to prepare for your next important call
-
Customer story
P&V automates digital customer journeys and appointment scheduling
-
Customer story
Stroke Care Telecarts - Belfast HSCT
-
Article
Telenor interview: Enterprise cybersecurity challenges and solutions
-
Article
How do secure collaboration tools benefit privacy-conscious organizations?
Nov 4, 2022 4 min read -
Customer story
Federal Employment Agency (BA) in Germany
-
Article
How does business continuity planning mitigate cyber attacks?
-
Article
Make your video meetings a custom branded experience
-
Product update
What's new in version 30 of Pexip Infinity self-hosted?
-
News
Pexip launches Marketplace to showcase applications, integrations, and partnerships
-
Customer story
Vivaldis helps job seekers faster with Pexip Engage
-
Customer story
Company Webcast creates a more scalable video solution for webinars with Pexip
-
News
Pexip gives Google Meet users greater flexibility to join calls from third-party video conference systems
-
Customer story
How Tyles improved their efficiency and customer experience
-
Article
How does PwC Australia securely and sustainably connect global clients and teams?
-
Article
10 most common time management mistakes and how to avoid them
-
News
Hippo Technologies and Pexip partner to scale the delivery of next generation virtual care
-
Article
One-Touch Join: Now available in the Pexip Cloud
-
Customer story
Bike Center brings order to chaos with Pexip Engage
-
White paper
Using telehealth to manage chronic diseases
-
Article
3 ways to ensure business continuity with secure video conferencing
-
Article
Why is the "video economy" the future of video communication?

-
Article
How James Cook University embraces sustainable digital transformation

-
Article
The future is calling. This is how we're answering
-
Customer story
How Nutreco Skretting reduced their business travel and made joining remote meetings easier
-
Article
From meetings to missions: the future of collaboration
-
Report
KLAS First Look: Pexip Health
Aug 23, 2022 -
Customer story
How Queensland Health scaled its telehealth solution and brought healthcare into patients’ homes
-
Product update
What's new in version 29 of Pexip Infinity self-hosted?
-
Customer story
How Songwon Industrial Group made video conferencing a part of everyday work life
-
News
Access Telehealth Interpreters More Easily with Pexip, LanguageLine Solutions
-
News
Pexip and Rocket.Chat partner to provide an integrated chat and video solution for secure, data-sovereign communications
-
News
Pexip and Rocket.Chat for secure, modern, on-premise communication

-
Customer story
How Paulding County, GA’s detention facilities streamlined remote court proceedings
-
Customer story
McLeod Health brings students, providers, and parents together through school-based telehealth
-
Article
5 must-have video conferencing features to power government hybrid working

-
Article
Pexip Service for Microsoft gets an upgrade

-
Product update
What's new in Pexip Engage's V2?
-
Article
Accessible meetings: How accessibility is at the heart of Pexip's product designs

-
Customer story
How Solidaris exceeded their pre-pandemic appointment numbers
-
Product update
Pexip Secure Meetings for Justice solution released toda
.png?width=41&name=gillian%20(cropped).png)
-
Product update
What's new in version 28 of Pexip Infinity self-hosted?
-
Article
What is the future of telehealth in Australia?

-
Article
What is e-waste, and how can you make your technology more sustainable?
-
News
Pexip confirms its return to the ISE Show in Barcelona to showcase the platform that is powering the video economy
-
News
Trond K. Johannessen takes the helm as Pexip CEO
-
Article
Key cybersecurity considerations for video conferencing safety
-
Product update
Pexip Engage: a video enabled customer engagement application released today
-
News
Skedify becomes “Pexip Engage” - a video-enabled customer engagement application
-
Article
How to effectively schedule appointments to streamline process and boost your ROI
-
Customer story
How Skill Builders improved talent mobility with Pexip Engage
-
News
Pexip is first to offer Microsoft Teams Cloud Video Interop (CVI) in Microsoft Azure Government Cloud
-
Article
What's new on the Pexip Service?
-
Article
What does it take to secure your most critical video meetings?
-
News
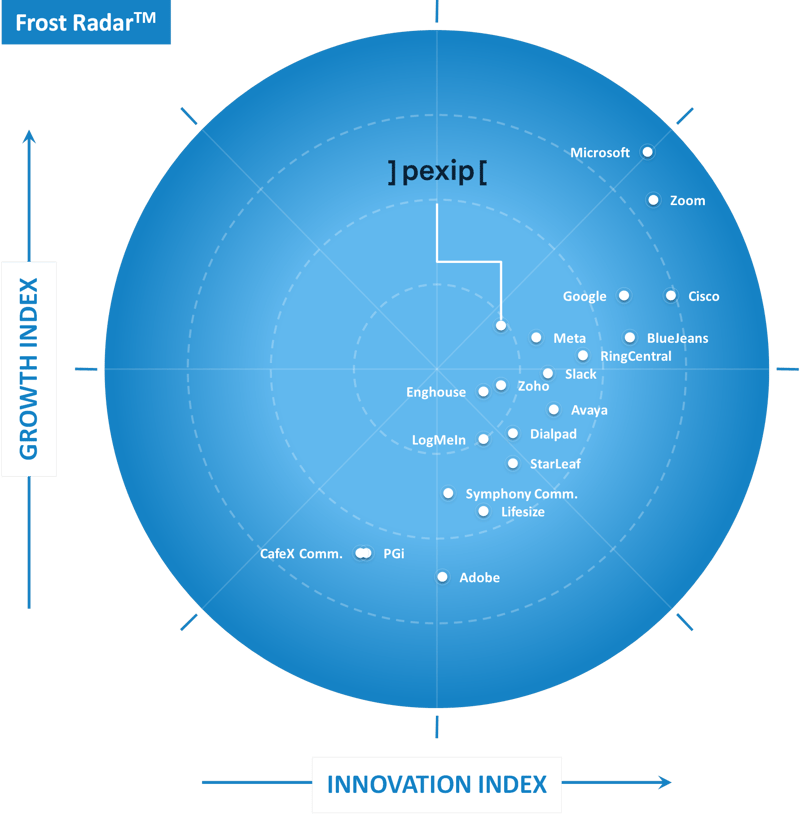
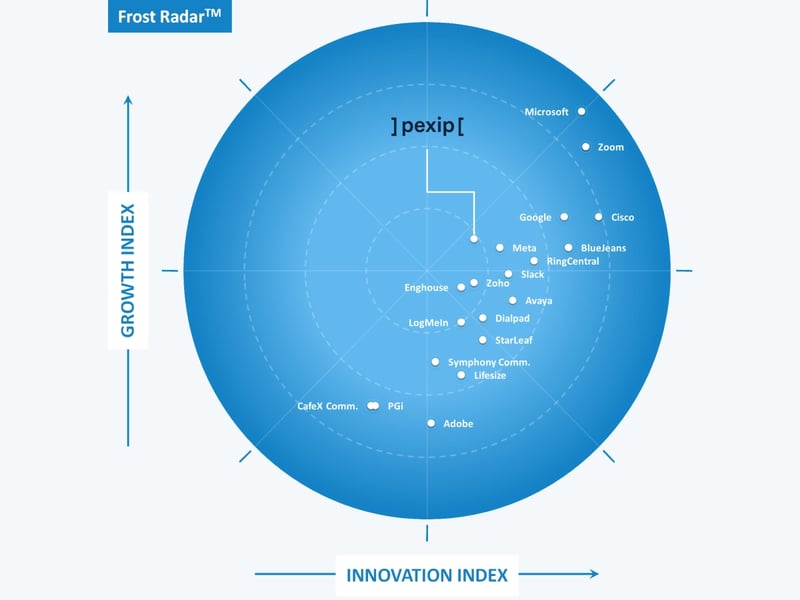
Pexip recognized by Frost & Sullivan as a Growth and Innovation Leader in the 2021 Frost Radar™ for Cloud Meetings and Team Collaboration Services
-
Article
4 mega trends that are shaping the new era of video communication
-
News
Pexip now available in the Microsoft Azure Marketplace
-
News
Pexip appoints Trond K. Johannessen as Chief Executive Officer
-
News
Pexip Government Cloud achieves FedRAMP “In Process” designation
-
Product update
What's new in version 27 of Pexip Infinity self-hosted?
-
Article
Enterprise Room Connector just got even better
-
Article
What are the 3 key customer engagement trends in 2022?

-
Article
Top 3 predictions how video communication and collaboration will reshape organizations in 2022
-
Article
Zero-trust adoption for secure video conferencing
-
News
Almost 70% of enterprises say security and privacy are key considerations for video meetings
-
News
Pexip statement on Log4j vulnerability
-
News
Frost & Sullivan commends Pexip for redefining the delivery of healthcare services

-
Article
Data concerns your organization needs to start addressing right now
-
Article
Fail fast, learn faster: building an adaptable collaborative culture
-
News
Pexip wins European Small and Mid-Cap award
-
Article
A step-by-step guide to achieve Microsoft Teams interoperability using Pexip CVI
-
News
Pexip acquires Skedify
-
Article
How can the right business tools help law firms grow?
-
Article
Is your law firm's video conferencing platform secure?

-
News
The Asia Pacific video conferencing market evolution
-
Customer story
How NHS Wales modernized and scaled up their video conferencing in response to the Covid-19 pandemic
-
Article
5 questions you should be asking about your video conferencing data
-
News
Pexip Named a Challenger in the 2021 Gartner® Magic Quadrant™ for Meeting Solutions
-
Article
What are the benefits of video customer engagements for the retail sector?
-
Article
4 ways the Enterprise Room Connector simplifies your video meeting room experience
-
Article
Pexip launches Direct Peering
-
Webinar
Schrems II: What’s next for your personal data & digital privacy?
-
Article
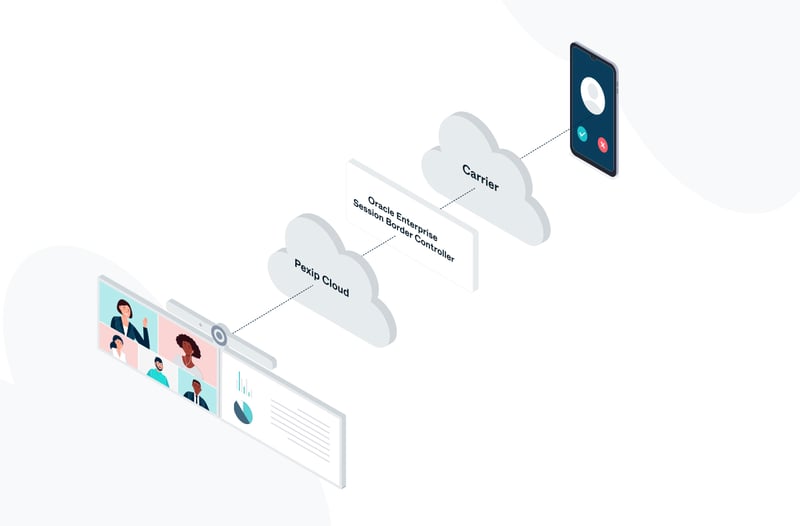
Oracle E-SBC now enabling BYOC on the Pexip Service platform
-
News
Pexip received a significant contract extension with the Defense Information Systems Agency in the US
-
Article
4 ways video empowers government to citizen (G2C) communication

-
News
Pexip expands Cloud Video Service in South America
-
Article
What is meeting equity, and why do inclusive meetings matter?
-
Article
How can government agencies prepare for the hybrid workforce?
-
Customer story
How Telehealth Tasmania expanded virtual healthcare and communications
-
Customer story
How Euro-Information simplified secure video appointments with clients
-
Product update
What's new in version 26 of Pexip Infinity self-hosted?
-
White paper
Pexip's Private Cloud: A game-changer for meeting solutions?
-
White paper
How video is proving its value in healthcare
-
Article
How to optimize internal collaboration in financial organizations
-
Article
Video banking: Bridging digital banking and the bank branch
.jpeg?width=41&name=Michael%20Whittam%20(1).jpeg)
-
Customer story
How the Joint Court of 6 Caribbean Regions moved all proceedings to a virtual format
-
Article
Introducing Pexip Control Center
-
Customer story
How VolkerWessels Telecom reduced travel and time expenses with Pexip
-
Webinar
Digital finance in the post-pandemic world
-
Article
How to optimize your home office lighting set-up for video conferencing

-
Article
How integrated telehealth streamlines clinical workflows
-
Article
How to improve video conferencing audio quality (and stop that echo once and for all)
-
Article
Choosing a video banking platform that protects your customers' data
-
News
Pexip Service now supports Avaya video conferencing systems
-
News
Pexip awarded the Carnegie Sustainability Award 2021
-
Article
How to optimize your telehealth metrics program

-
News
Pexip wins "Best Virtual Care Solution"
-
Article
Completing a virtual IPO using video: the Pexip story

-
News
Pexip Health recognized by KLAS Research in First Look Report
-
Article
6 ways to use video meetings in banking and financial services
-
Article
7 trends driving video collaboration in the modern workplace
-
Article
Pexip and Google Meet for a future-proof, hybrid workforce
-
Article
Modernize your workplace with a video interoperability strategy
-
News
Pexip Health wins “Best Telehealth Platform” award
-
Article
How will video communication transform consumer banking in 2021?
-
Customer story
How New Mexico Supreme Court enabled virtual hearings with Pexip
-
Customer story
How Pexip helped Hampshire Hospitals provide quality, multi-disciplinary healthcare services
-
Article
In the age of IT outsourcing, trust is everything

-
Article
Video communication: How will Gen Z revolutionize the workplace?
-
News
Pexip seeks to reimagine virtual meetings using NVIDIA AI and deep learning technology
-
News
Pexip named a best place to work for the second year in a row
-
Article
Taking video to the next level with AI
-
Article
Is your video conferencing solution future proof?
-
Article
How 'The Pexip Way' helped us through the challenges of 2020

-
Article
How the post-pandemic fallout will reshape the office in 2021

-
Article
Encryption in the Pexip ecosystem
-
Article
How can telehealth help you achieve the Quadruple Aim this year?
-
Article
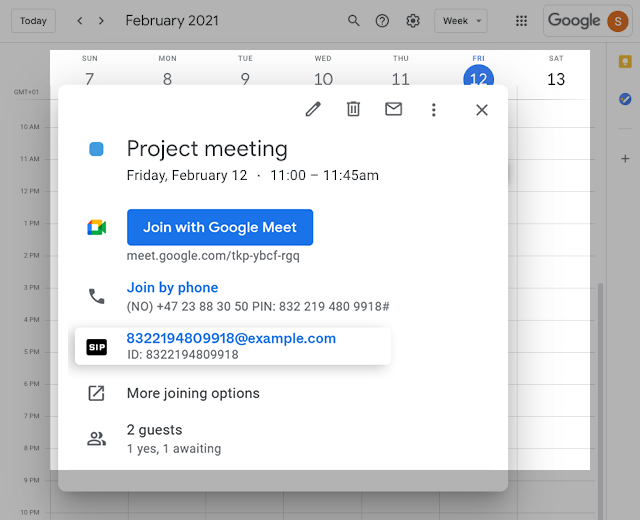
Joining Google Meet meetings with Pexip just got even easier
-
Article
Kayye’s Krystal Ball: Tech trends in 2021 & the year of Pexip

-
Webinar
Using telehealth to streamline clinical workflows
-
Article
Democratization: is this the future for video conferencing?
-
Article
4 priorities shaping the future of workplace communications
-
Article
Three keys to telehealth adoption
-
Article
The top 5 tips for Customer Success in a SaaS company

-
News
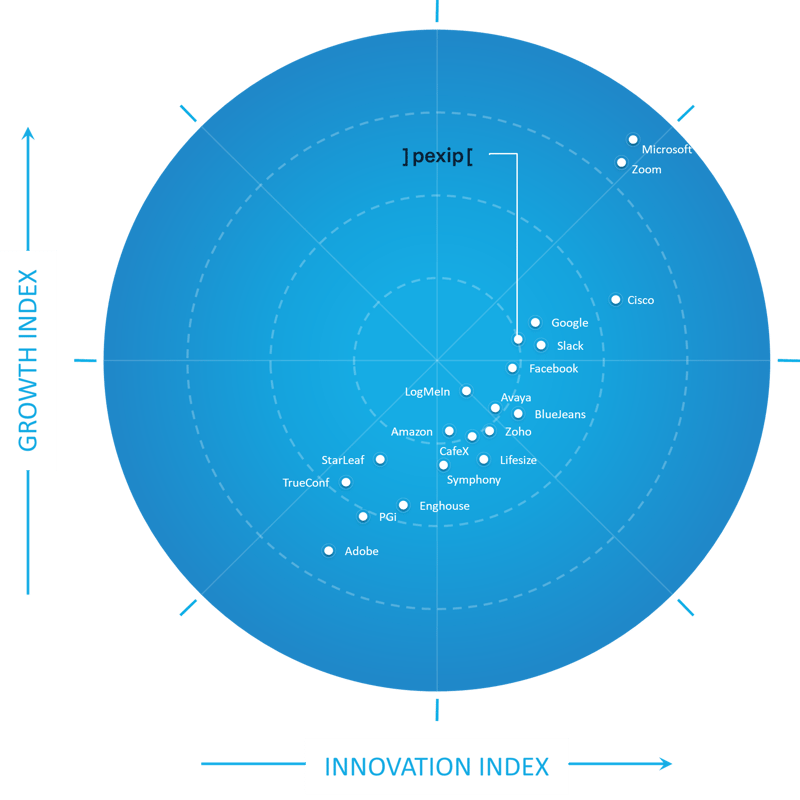
Pexip recognized by Frost & Sullivan as a Growth and Innovation Leader in the 2020 Frost Radar™ for cloud meetings and team collaboration services
-
Article
How to enhance telehealth IT security in 2021
-
Customer story
How James Cook University updated its legacy video technology systems and optimized the ROI of their video strategy
-
Article
How telehealth supports chronic disease management
-
News
Pexip wins Frost & Sullivan’s 2021 Customer Value Leadership award
-
Article
Why your internet connection could be behind your video fatigue (and how to manage it)
-
News
Pexip announces native integration with Epic, the world’s largest Electronic Health Record System provider
-
Article
Improving virtual care with Pexip Health
-
Article
What does it mean to be meeting-agnostic?
-
News
Pexip video conferencing solutions now available on GSA multiple award schedule through immixGroup
-
Article
How to prevent video meeting fatigue
-
Article
Virtual experiences for the whole family
-
Article
Pexip meetings are all about quality
-
News
Latest APAC news & 2020 in review
-
News
Pexip accelerates long-term annual recurring revenue Target - delivers ARR growth of 70%
-
News
Introducing Pexip Private Cloud
-
Article
Google transport-wide congestion control
-
Article
Breaking the sound barrier
-
Article
New meeting experience on iOS for Pexip Service
-
Article
Bring Your Own Carrier, now available from Pexip
-
Article
Pexip introduces custom branded meetings

-
Article
Why banking needs people-first video conferencing
-
News
Telstra and Pexip partner to create seamless video communication experiences
-
Article
AV security: how to protect your audiovisual tech
-
Article
Using video for remote court proceedings
-
Article
Keep telehealth simple to use for providers and patients
-
Article
Pexip’s Microsoft Teams Interoperability Service Offers Unprecedented Flexibility

-
News
Pexip named a Visionary in Gartner Magic Quadrant for meeting solutions for the second year in a row
-
Customer story
Fortune 500 Healthcare Company
-
Customer story
Large Enterprise Banking Company
-
Customer story
Large Enterprise Consumer Products Company
-
Customer story
Global 500 Pharmaceuticals Company
-
Customer story
Global 500 Retail Company
-
Article
Key privacy and security considerations when choosing a video conferencing solution
-
Customer story
State & Local Government
-
Customer story
Eifrid Systems
-
Customer story
Ternium Steel Manufacturing
-
Webinar
Driving collaboration in the evolving healthcare workplace
-
News
Pexip in Dutch Het Financieele Dagblad. Video communication after the crisis
-
Article
8 tips for smoother, more engaging client meetings
-
News
Video communications company, Pexip, announces strong internal growth momentum
-
Article
Upholding privacy and security: How Pexip aligns with the 14 Cloud Security Principles
-
Article
The EU-U.S. Privacy Shield Invalidation: Pexip’s response and preparedness

-
Customer story
Government of Northwest Territories – Canada
Aug 17, 2020 -
Customer story
Iberdrola Inmobiliaria
-
Customer story
Mantena
-
Customer story
Odfjell Drilling
-
Customer story
Realdania
-
Customer story
Royal Swedish Academy of Engineering Sciences
-
Customer story
Norwegian Government Security and Service Organisation
-
News
Pexip listed in the Epic app orchard

-
News
Pexip announces another record quarter
-
Article
Share your screen from iPhones and iPads
-
Product update
What's new in Pexip Infinity version 24?
-
Webinar
As you transition back to the office, how can you prepare for the future of work?
-
News
Pexip to acquire Videonor’s base of enterprise customers
-
Article
Transitioning back to the office: How video interop can support your hybrid workforce

-
Article
The future of virtual care in Australia: Queensland telehealth transformation

-
Article
Transitioning back to the office – using video to stay connected

-
Article
Podcast: Fueling a successful remote work strategy with video

-
Article
Join meetings without a camera or microphone connected
-
Article
Podcast: Building a scalable video conferencing infrastructure
-
Article
Women in technology supported by The Pexip Way

-
Article
CommuniCloud brings Pexip video communications to Telehealth Tasmania
-
Article
Podcast: Why video interop is key for business continuity
-
Article
Podcast: How to get more ROI from existing video conferencing solutions
-
Article
Podcast: How video fits into your long-Term digital workplace strategy
-
Article
RPA Sydney - virtual care: providing telehealth services in Australia
-
Article
Video conferencing deployment options: Choosing the best fit for your organization
-
News
Pexip listed on the Oslo Stock Exchange after the first fully-virtual IPO in Norway
-
Article
Podcast: Breaking down video conferencing privacy and security
-
Article
Secure cloud video conferencing: 3 key areas to consider
-
Article
Combining freedom and responsibility - The Pexip Way
-
Article
How to better secure your video meetings
-
News
Pexip announces record high sales growth
-
Article
Data privacy is paramount for video communications, and Pexip is committed to keeping your data secure
-
Article
How to support mental health and well-being for remote workers
-
Article
Join Teams and Hangouts directly with Trusted Devices
-
Article
How Pexip created a telework policy to support its culture of remote work
-
Article
Pexip named a Best Place to Work by Washington Business Journal
-
Article
Large format meetings in Pexip
-
Article
Pexip achieves ISO 27001 certification for information security management
-
Article
Easy getting started guide for video meetings on the Pexip Service
-
Article
How to plan for a successful video meeting

-
Webinar
Resfria möten i offentlig sektor
-
Article
How video can support remote learning
-
Article
Making it easier to join any meeting
-
Product update
What's new in Infinity version 23?
-
Article
Video communications: The natural choice for business continuity in response to Coronavirus
-
Article
See meetings directly from your Office 365 account on iOS
-
News
Pexip named Frost & Sullivan’s 2020 Global Entrepreneurial Company of the Year
-
News
Pexip is first to bring AI-powered auto framing and intelligent layout to any meeting participant
-
Article
Just meet (let us take care of the technology)
-
Article
Why choose the Pexip meeting platform?
-
Webinar
How Helsinki University Hospital uses video for outpatient care
-
Article
View meetings directly from your Office 365 account on Android
-
Article
Pexip's Google Interop Service now supports branded domains
-
Article
Choosing the right telehealth platform: 5 factors to consider
-
Article
Share your screen from Microsoft Edge and Safari
-
Article
Pexip Partner Summit 2019
-
Product update
Pexip Infinity: What's new in version 22?
-
News
Pexip and Kinly sign global partnership agreement to expand in the visual collaboration market
-
Article
How Pexip built a video conferencing platform made for the future

-
News
Pexip named a Visionary in 2019 Gartner Magic Quadrant for Meeting Solutions
-
Article
Using Pexip for online classes: A student’s perspective
-
Article
Helping government migrate to Microsoft Teams
-
Product update
Pexip Service Android 3.1 release: Mute current & future guests on entry and much more
-
News
Pexip Service Android 3.1 release: Mute current & future guests on entry and much more
-
Webinar
How Indiana University improved student attendance rates by 50%
-
Article
How will telework initiatives drive flexibility in government workforces?
-
News
New research finds that mix of in-person and distance learning cuts absenteeism by 50 percent
-
Article
Microsoft Inspire + Ready 2019. Together we achieve more
-
Article
Expanding the capabilities of Microsoft Teams Room Systems
-
News
Pexip to offer free Cloud Video Interop capabilities for Microsoft Teams Rooms and Surface Hub 2 customers
-
Article
InfoComm reflections: Thank you, partners!
Jun 24, 2019 -
News
Pexip bolsters healthcare focus to address growing demand for telemedicine
-
Article
Pexip: Our brand story
-
Article
Migrating from Skype for Business to Microsoft Teams using Pexip Infinity
-
News
Pexip and Videxio announce merger
-
Microsoft Ignite 2018 - A quick Pexip recap
-
Article
Region Västerbotten & Microsoft (in Swedish)
-
What’s new in Pexip Infinity 21?
-
Webinar
Education: How Indiana University reduced absenteeism with 50% using remote access education
-
Article
MeetingConnect: Scan to join technology for video meetings
-
Article
Pexip Infinity for Microsoft Teams - a quick demonstration
Jun 10, 2019 -
Article
Pexip Infinity - a dynamically scalable meeting platform
Jun 10, 2019 -
News
Pexip unveils expanded Channel Partner program to meet demand for flexible video conferencing
-
News
Pexip launches cloud-based video interoperability service for Microsoft Teams
-
News
Perception is reality: Why Pexip’s #1 ranking matters
-
News
Pexip adds Polycom Trio to Portfolio of Video Conferencing Systems Registrable to the Pexip Service
-
News
Pexip ranks #1 in brand perception survey from Wainhouse Research
-
News
Videxio and Pexip announce merger approval
-
Article
Introducing MeetingConnect: Supporting Teams, Meet, Webex & Zoom video meetings
-
Article
Legacy video infrastructure face end-of-life? Here’s what you need to know
-
Article
The 9 most frustrating barriers to joining video meetings
-
Product update
Pexip Infinity v20 is now available
-
News
Videxio and Pexip announce intention to merge
-
Article
A demonstration of Pexip Infinity for Microsoft Teams
-
News
Pexip announces availability of its Microsoft-certified video interoperability platform for Microsoft Teams
-
Article
Top 5 collaboration trends for 2019
-
Article
Why security is imperative for video meetings
-
News
Pexip featured at Google Cloud Next 2018
-
Article
5 things every huddle room needs
-
Article
Introducing one-time-use meeting rooms (Beta)
-
News
Pexip named a “Cool Vendor in Unified Communications and Collaboration”
-
Article
How to build a great culture for remote workers
-
News
Pexip appoints Odd Sverre Østlie as Chief Executive Officer
-
Article
Pexip Infinity 17 is here
-
News
Pexip appoints Christopher Ford as Vice President of Sales for Americas region
-
News
Pexip appoints Linda Christin Hoff as CFO
-
News
Pexip to deliver video tele-conferencing (VTC) interoperability for Microsoft Teams
-
News
MVP Ståle Hansen to provide private workshops at Microsoft Ignite
-
Product update
Pexip Infinity V16 available
-
Article
SfB Broadcast – Episode 49: 3 ways to bring your VTC into a modern meeting
-
News
President Donald Trump introduces VA Video Connect
-
News
Pexip Infinity Fusion certified as interoperability solution for Microsoft Skype for Business Server
-
Article
What is a Virtual Meeting Room and what are the benefits?
-
Article
Nordea hires 60 new advisors after strong growth for video meetings
May 7, 2017 2 min read -
Webinar
Empower your hybrid workforce with Microsoft Teams & Pexip
-
Report
Pexip: A Challenger in the 2021 Gartner Magic Quadrant for meeting solutions
-
Report
Find out why enterprise users rate Pexip #1.
-
A quick overview of Pexip's CVI solution for Microsoft Teams
-
A quick overview of Pexip's Gateway Solution for Google Hangouts Meet
-
A quick overview: Pexip Service endpoint registration & management solution
-
A quick overview: Pexip One-Touch Join
-
Article
Leading In A Changed World
-
eBook
The ultimate guide to hybrid & virtual court hearings
-
Webinar
You’ve decided on Microsoft Teams – now what?
-
Webinar
Trends and expectations for enterprise collaboration and communication
-
Webinar
Meeting equity in the hybrid workplace
-
Report
Frost & Sullivan - 2021 global customer value award
-
Report
2021: The state of video communication in large enterprises
-
Report
Frost & Sullivan Radar™ Benchmark 2021 report
%20header.jpg?width=800&name=Secure%20meetings%20Pillarpage%20(primary%20solition)%20header.jpg)

.png?width=800&name=Copy%20of%20Blog%20header%20(2).png)



.png?width=800&name=Copy%20of%20Blog%20header%20(1).png)
-1.jpg?width=800&name=iStock-1290753047%20(1)-1.jpg)





.png?width=800&name=Pexip-Connect-for-Google-Single-Screen-blog%20(1).png)



.png?width=800&name=marius%20blog%20image%20(1).png)










.jpg?width=800&name=v38%20laptop%20blog%20(1).jpg)











.png?width=800&name=Access-control-ebook-thumbnail%20(1).png)



.jpg?width=800&name=Defense%20pillar%20page%20bg%20(1).jpg)

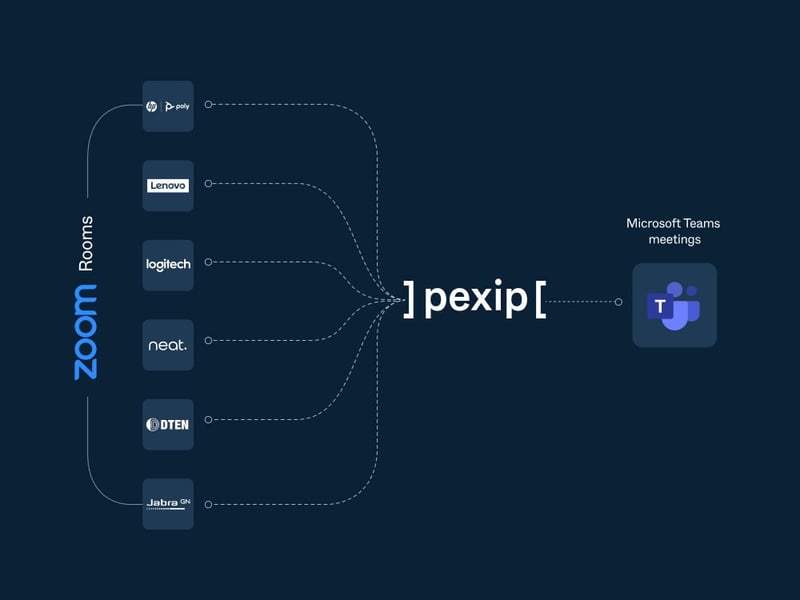



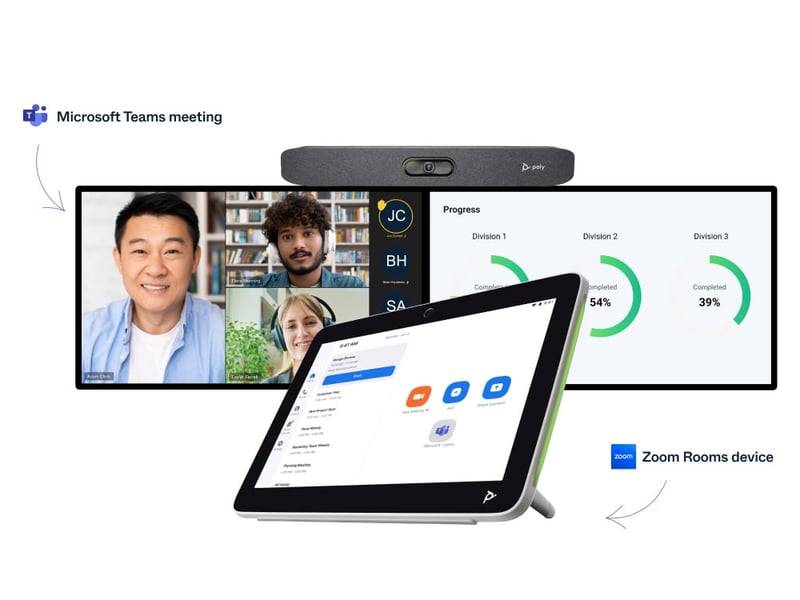






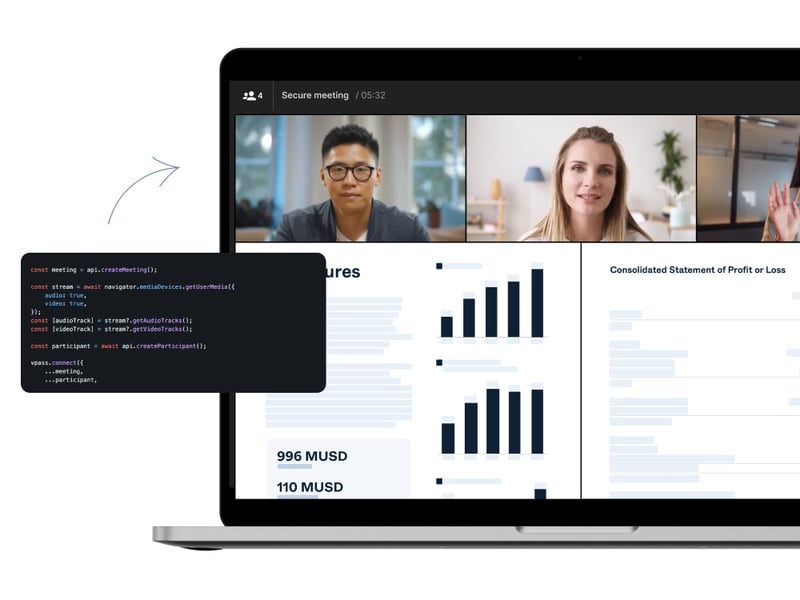

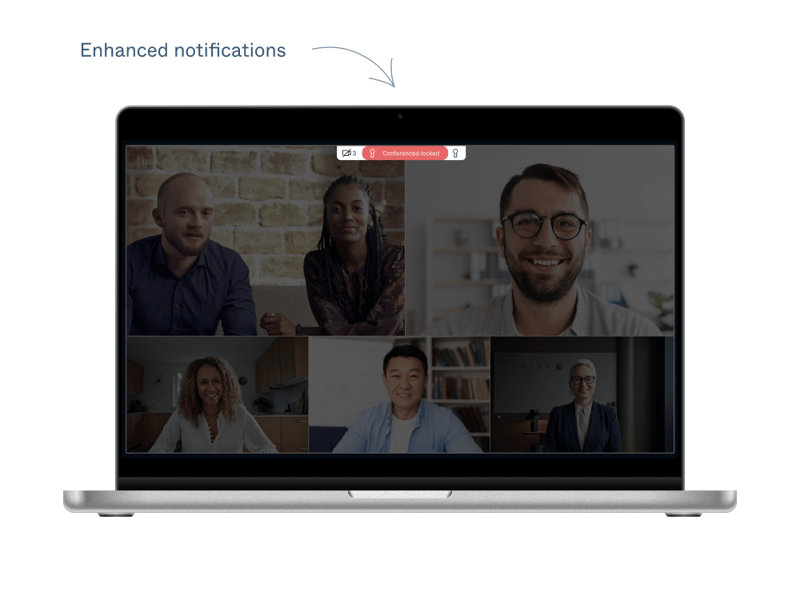



.jpg?width=800&name=blog%20purple%20(1).jpg)

.png?width=800&name=A%20step-by-step%20guide%20to%20join%20Teams%20Meetings%20from%20Zoom%20Rooms%20using%20Pexip%20Connect%20(2).png)








.png?width=800&name=Untitled%20design%20(6).png)

.png?width=800&name=Untitled%20design%20(5).png)





.jpg?width=800&name=1%20(1).jpg)
.jpg?width=800&name=policy%20server%203%20(1).jpg)

.jpg?width=800&name=blog%20(3).jpg)





.jpg?width=800&name=Blog%20(2).jpg)











.jpg?width=800&name=2%20blog%20(3).jpg)





.jpg?width=800&name=Retail-multi-device-scheduling-flow-pexip-engage%20(4).jpg)












.png?width=800&name=Dial_directly_between_MTR_and_other_meeting_room_devices_blog%20(1).png)



















































.webp?width=800&name=How%20retail%20banks%20can%20win%20customers%20with%20scheduled%20video%20appointments4_3%20(1).webp)







.webp?width=800&name=3%20Unite%20your%20meeting%20rooms%20with%20a%20Teams-like%20experience%20(1).webp)











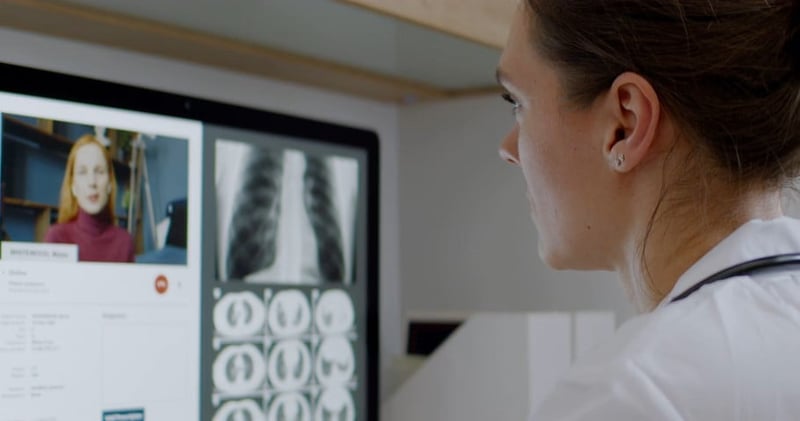














.jpg?width=800&name=glenn-carstens-peters-npxXWgQ33ZQ-unsplash%20(1).jpg)

.jpg?width=800&name=james%20cook%20university(2).jpg)


-1.jpg?width=800&name=couple-talking-to%20financial-advisor-1-web-min(1)-1.jpg)






.jpg?width=800&name=iStock-1309489753%20(1).jpg)
%20(1).jpg?width=800&name=iStock-1254704794%20(1)%20(1).jpg)












.jpeg?width=800&name=iStock-1215890713%20(1).jpeg)




.jpg?width=800&name=iStock-1284041267%20(1).jpg)









-1.jpg?width=800&name=2021%20Award%20Web%20Banner%20-%20Pexip(5)-1.jpg)

.png?width=800&name=shutterstock_2179965709-min(1).png)




%20(1).jpg?width=800&name=iStock-1048663072%20(2)%20(1).jpg)


.jpg?width=800&name=iStock-1299152059%20(1).jpg)

-1.jpg?width=800&name=iStock-1265245223%20(1)-1.jpg)




-1.jpg?width=800&name=iStock-1269341639%20(1)-1.jpg)

_2.jpeg?width=800&name=iStock-1214822053-(1)_2.jpeg)
.jpg?width=800&name=iStock-1223889856%20(2).jpg)




















-min.jpg?width=800&name=iStock-1244526088%20(1)-min.jpg)




-min-2.jpg?width=800&name=iStock-1214479802%20(1)-min-2.jpg)
















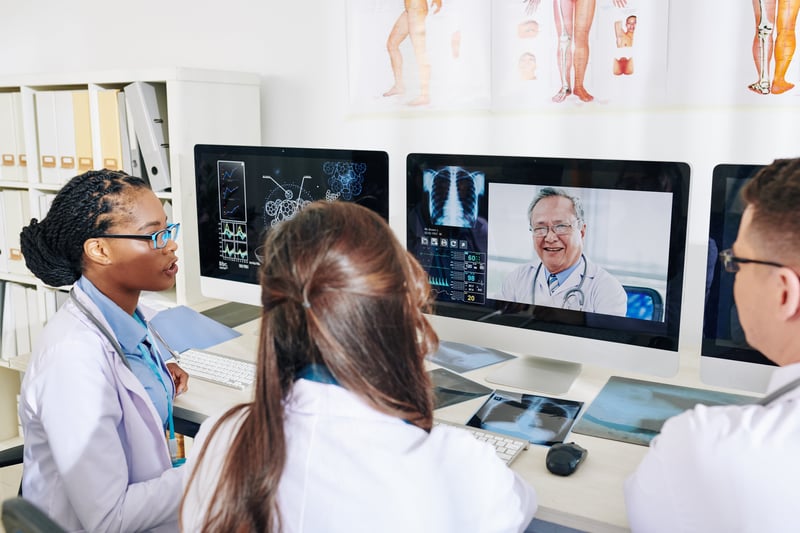





.jpg?width=800&name=Pexip-153%20(1).jpg)
-min.jpeg?width=800&name=offset_100144%20(1)-min.jpeg)



.png?width=800&name=Cream%20Polaroid%20Heart-Shaped%20Photo%20Collage(1).png)







-1.jpg?width=800&name=iStock-1221803375%20(1)-1.jpg)
-1.jpeg?width=800&name=video-system-with-content-sharing%20(1)-1.jpeg)
















.jpeg?width=800&name=AdobeStock_306636176%20(3).jpeg)

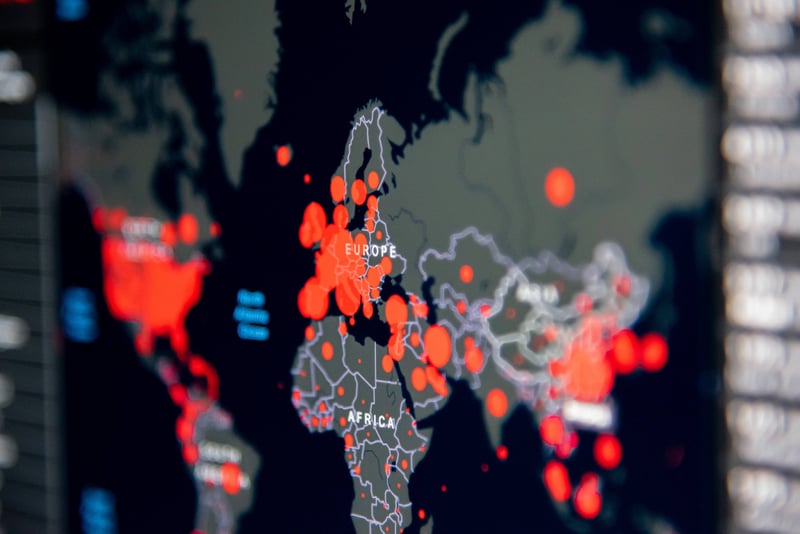







-%20Tech%20Validate%20-%20Pexip%20Case%20Study%20HBD.png?width=800&name=Norwegian%20Government%20Security%20and%20Service%20Organisation%20(Departementenes%20Servicesenter)-%20Tech%20Validate%20-%20Pexip%20Case%20Study%20HBD.png)




-1.jpeg?width=800&name=D-BNE-Bridge-River-2-CBD-Rise-1174707895_2125x1416%20(1)-1.jpeg)











.jpg?width=800&name=Pexip-152-min%20(1).jpg)


.jpeg?width=800&name=meeting-room-1%20copy-min%20(1).jpeg)



.jpeg?width=800&name=Pexip%2026-min%20(1).jpeg)


































-1.jpg?width=800&name=valentino-funghi-41237-unsplash%20(1)-1.jpg)







.jpg?width=800&name=Low_Resolution_JPG-VC%20Herman%20Miller%20Lifestyle%206%20(1).jpg)